Ever wondered how Stable Diffusion, DALL-E 3, or Midjourney transform simple text into stunning images? The secret is diffusion models, a revolutionary AI technology that's changing how we create visual content. In this guide, we'll break down exactly how diffusion models work in plain English, no computer science degree required.

If you've ever typed "a cat wearing sunglasses on a beach" into an AI image generator and watched it create exactly that, you've witnessed diffusion models in action. But what's actually happening behind those loading screens? Let's dive into the fascinating science that makes AI art possible.
What Exactly Are Diffusion Models? (Simple Explanation)
Think of diffusion models like a sculptor working in reverse. Instead of starting with a block of marble and chipping away to reveal a statue, diffusion models start with pure chaos, digital noise that looks like TV static, and gradually remove the randomness to reveal a beautiful image.
Here's the easiest way to understand it: imagine taking a photo of your dog and slowly adding more and more blur and pixelation until it becomes completely unrecognizable static. A diffusion model learns this "destruction process" during training, then learns to run it backwards. When you want to create a new image, it starts with random noise and systematically removes that noise step-by-step until your text description emerges as a clear picture.
This approach is fundamentally different from older AI art generators. Traditional GANs (Generative Adversarial Networks) tried to create images in one giant leap, which often resulted in weird artifacts and inconsistencies. Diffusion models take hundreds of tiny steps, making the process more controllable and producing higher-quality results.
The Two Critical Phases: Training and Generation
Phase 1: Forward Diffusion (How the AI Learns)
During the training phase, the diffusion model learns by watching millions of images get destroyed. Here's exactly what happens:
Step 1 - Starting Point: The model begins with a real photograph from its training dataset, let's say a picture of a golden retriever playing in a park.
Step 2 - Gradual Corruption: The system adds tiny amounts of random noise to the image. Not all at once, but in perhaps 1,000 small steps. After step 1, the image looks almost identical. After step 100, it's getting fuzzy. After step 500, you can barely tell it was a dog. After step 1,000, it's complete random static.

Step 3 - Pattern Recognition: At each step of this destruction process, the AI carefully records what the noise looks like and how much was added. It's building a mental map of "this is what step 247 looks like when destroying a dog photo."
Step 4 - Massive Repetition: This process repeats for billions of images across every category imaginable, landscapes, people, objects, animals, abstract art, everything. The model learns the mathematical patterns of how organized visual information degrades into chaos.
The brilliant insight here is that if you can learn the path from order to chaos, you can also learn to walk that path backwards, from chaos to order.
Phase 2: Reverse Diffusion (Creating New Images)
When you type a prompt like "a steampunk robot reading a newspaper in a Victorian caf --," here's the magic that happens:
Starting with Pure Noise: The model generates a rectangle of completely random pixel values, pure digital static with zero meaningful information. This is your starting canvas.
Text Understanding: Your text prompt gets processed through a language model (typically CLIP) that converts your words into mathematical vectors the AI understands. These vectors become the "guiding star" for the entire generation process.
The Denoising Dance: Now comes the iterative refinement, usually 20 to 100 steps depending on quality settings:
- Step 1: The model looks at pure noise and asks, "If I'm trying to create a steampunk robot caf -- scene, which pixels should I adjust first?" It makes subtle changes, removing a tiny bit of randomness.
- Step 5: Vague shapes start emerging, dark regions that might become the robot, lighter areas that could be windows or lighting.
- Step 15: General composition becomes clear, you can tell there's a figure in the center, architectural elements around it, and a sense of depth.
- Step 30: Details sharpen, the robot's form becomes distinct, the newspaper takes shape, Victorian d, cor elements appear.
- Final Steps: Fine details emerge, gear mechanisms on the robot, text on the newspaper, wood grain on tables, steam effects, lighting reflections.
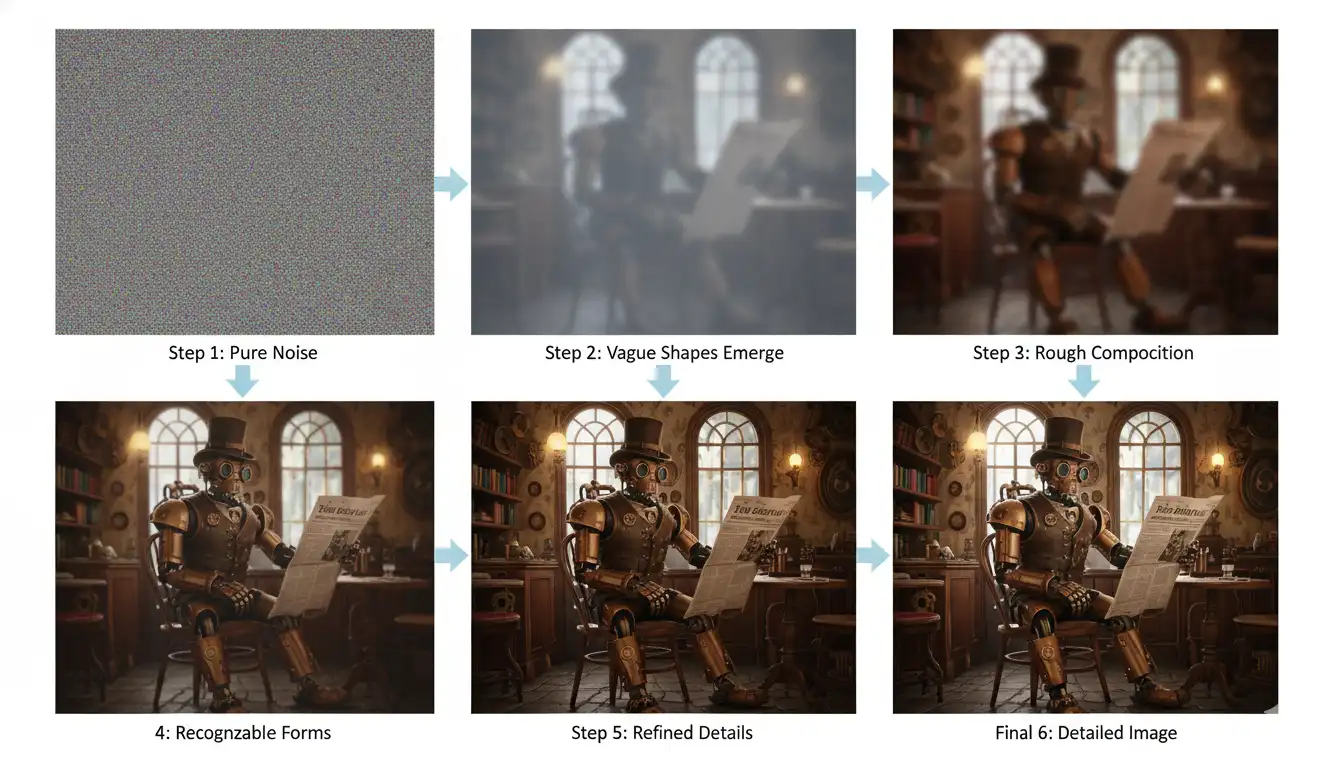
At each step, the model predicts "what noise should I remove to get closer to the text description?" and makes careful adjustments. It's like developing a Polaroid photo in slow motion, with each iteration revealing more detail and accuracy.
The Critical Technologies That Make Diffusion Models Work
Diffusion models aren't a single technology, they're a carefully orchestrated system of multiple AI components working together. Understanding each piece helps you grasp why they're so powerful.
1. U-Net Neural Network: The Noise Predictor
The U-Net is the brain of the operation. This specialized neural network has a unique architecture that looks like the letter "U" when diagrammed (hence the name). Here's what makes it special:
The Encoder Path (Downward): Takes your noisy image and compresses it into increasingly abstract representations. It's asking, "What are the fundamental structures and patterns here?"
The Decoder Path (Upward): Takes those compressed patterns and expands them back into a full-resolution image, predicting exactly what noise to remove.
Skip Connections (The Secret Sauce): Direct pathways between encoder and decoder layers preserve fine details that would otherwise be lost in compression. This is why diffusion models can maintain incredible detail while working with abstract concepts.
The U-Net has been trained on billions of images to recognize what "good images" look like at every level of detail, from broad composition down to individual textures.
2. CLIP Text Encoder: Understanding Your Words
CLIP (Contrastive Language-Image Pre-training) is the technology that bridges the gap between your text description and the visual concepts the model understands. It's been trained on hundreds of millions of image-caption pairs from across the internet.
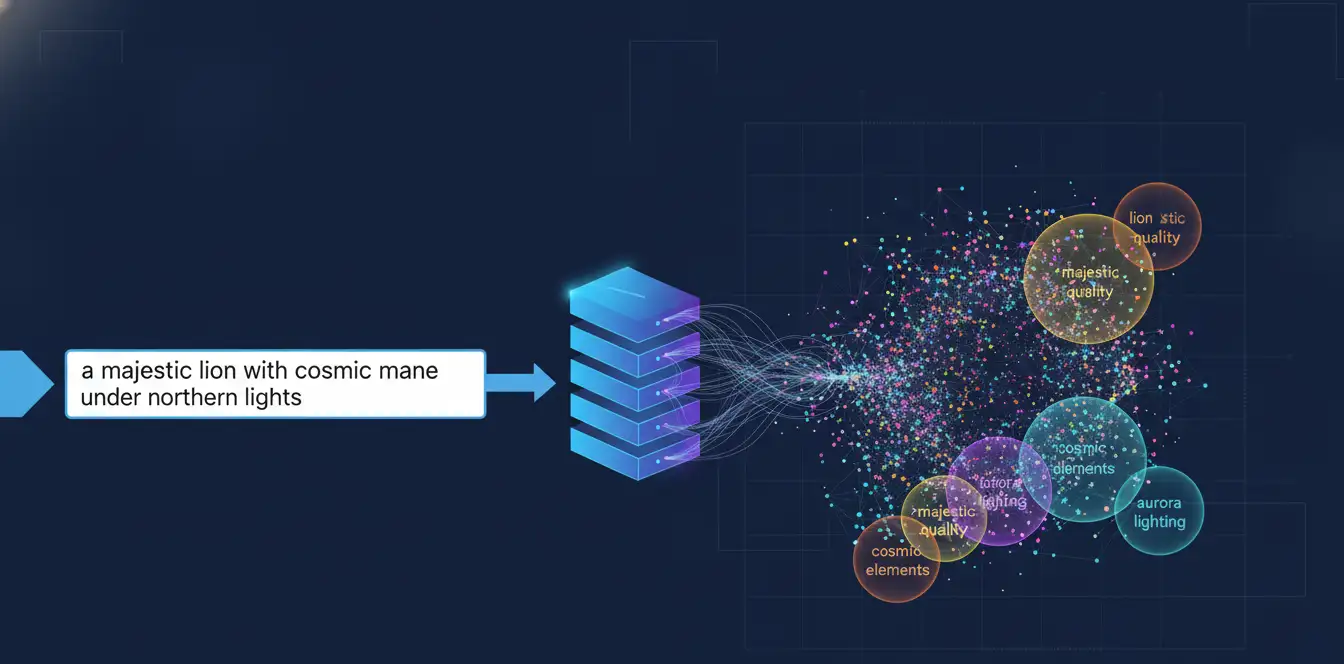
When you write "a majestic lion with a cosmic mane under the northern lights," CLIP converts that into a multi-dimensional mathematical vector that captures:
- The concept of "lion" and its typical visual features
- The modifier "majestic", regal poses, impressive presence
- The creative element "cosmic mane", space themes, stars, nebulae
- The setting "northern lights", aurora colors, nighttime, specific lighting
This vector guides every single denoising step, ensuring the emerging image aligns with your description.
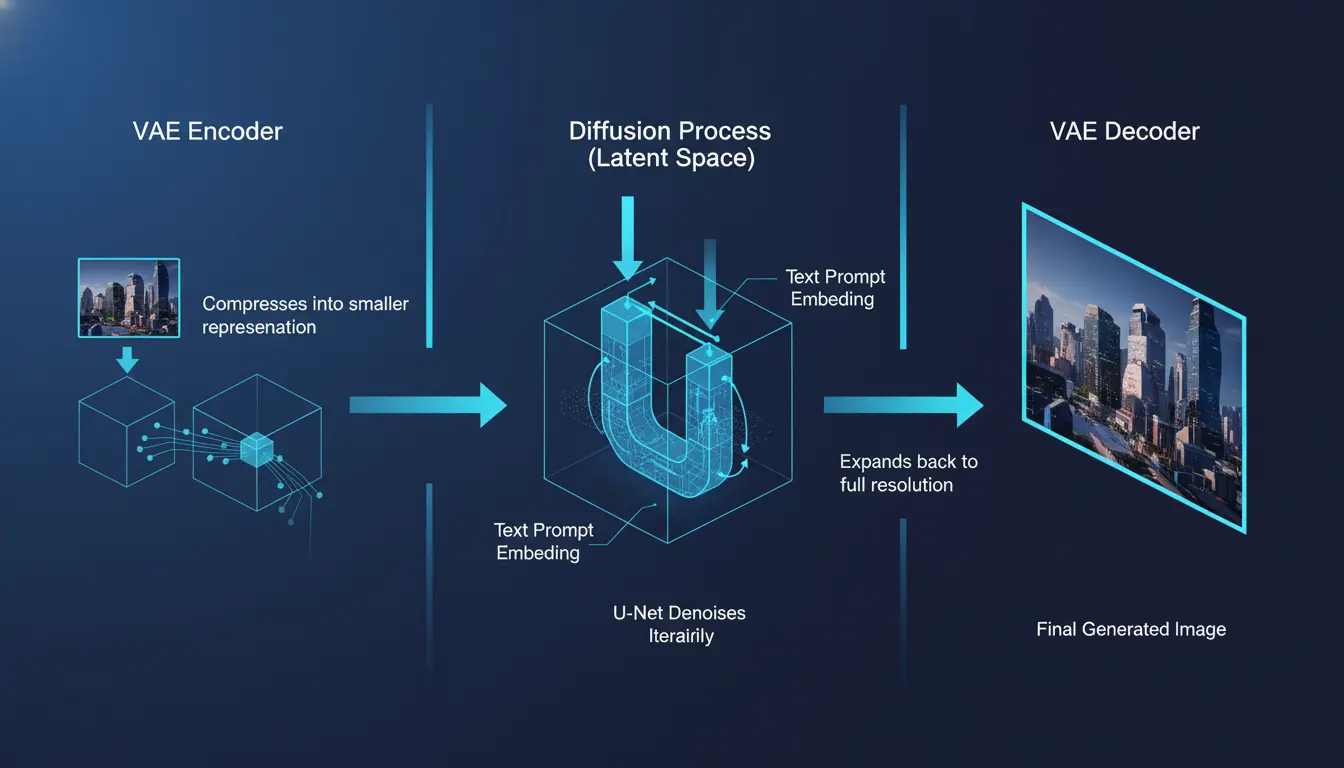
3. VAE (Variational Autoencoder): The Efficiency Engine
Here's a practical problem: full-resolution images are enormous. A single 1024-1024 pixel image contains over 3 million values to process. Doing 50 diffusion steps on that much data would take forever and require massive computing power.
The VAE solves this by working in "latent space", a compressed representation of images. Think of it like working with a blueprint instead of the full building:
Before Generation: Images are compressed 8x smaller in latent space (1024-1024 becomes 128-128). The diffusion process happens here, making it 64 times faster.
After Generation: Once the diffusion process completes in latent space, the VAE decoder expands the compressed result back to full resolution, adding back all the fine details.
This is why Stable Diffusion can run on consumer GPUs, it's working smarter, not harder.
4. Noise Scheduler: The Timing Controller
Not all denoising steps are created equal. The scheduler determines how much noise to remove at each step, and it follows a clever strategy:
Early Steps (1-20): Remove lots of noise aggressively. These steps establish the basic composition and major elements. Getting the general structure right is crucial.
Middle Steps (21-40): Moderate noise removal. Refining shapes, establishing relationships between objects, setting up lighting and atmosphere.
Final Steps (41-50): Very gentle noise removal. Adding fine textures, subtle lighting effects, small details. Too much change here could destroy the work done earlier.
Different schedulers (DDPM, DDIM, Euler, DPM++) use different mathematical approaches, which is why changing the scheduler in your AI art tool can dramatically affect your results even with the same prompt and seed.
Why Diffusion Models Dominate AI Image Generation in 2025
Diffusion models have become the industry standard, powering everything from Stable Diffusion XL to DALL-E 3 to Midjourney v6. Here's why they're so successful:
Superior Image Quality and Realism
Compared to older GAN-based generators, diffusion models produce images with:
- Better coherence: Objects look more realistic with proper proportions and physically plausible arrangements
- Superior details: Textures, lighting, and subtle effects are remarkably accurate
- Fewer artifacts: Less likelihood of weird distortions, uncanny faces, or impossible geometries
- Natural diversity: Multiple generations from the same prompt create genuinely different variations rather than slight modifications

Unmatched Prompt Understanding and Control
Modern diffusion models interpret complex prompts with impressive accuracy. You can specify:
- Multiple subjects with specific relationships: "a cat teaching a dog how to use a computer"
- Detailed styling: "in the style of Studio Ghibli, watercolor, soft lighting"
- Technical parameters: "shallow depth of field, 85mm lens, golden hour"
- Compositional elements: "centered subject, rule of thirds, dramatic perspective"
The integration with CLIP means the model understands both explicit instructions and nuanced artistic concepts.
Flexibility and Adaptability
Diffusion models can be adapted for numerous applications beyond basic text-to-image:
- Image-to-image: Transform existing images while preserving structure
- Inpainting: Intelligently fill missing areas or edit specific regions
- Outpainting: Extend images beyond their original boundaries
- Upscaling: Add realistic details to low-resolution images
- ControlNet: Guide generation with edge maps, depth maps, or poses
- Fine-tuning: Train on specific styles or subjects with relatively small datasets
Iterative Refinement Capability
Because diffusion works in steps, you have granular control over the generation process. Many tools let you:
- Stop early for sketch-like results (15-20 steps)
- Continue longer for maximum detail (100+ steps)
- Adjust guidance strength mid-generation
- Use img2img to iteratively refine outputs
This makes diffusion models more like artistic tools than black-box generators.
Different Types of Diffusion Models Explained
Not all diffusion models work exactly the same way. Understanding the variations helps you choose the right tool and settings for your needs.
DDPM (Denoising Diffusion Probabilistic Models)
The original diffusion approach developed in 2020. DDPM uses hundreds or thousands of steps to gradually denoise images, following a precise mathematical formula based on probability theory.
Strengths: Highest quality results, strong mathematical foundations, very stable generation process.
Weaknesses: Extremely slow, may require 1000+ steps for optimal results. Not practical for consumer applications.
Best for: Research purposes, situations where quality matters more than speed.
DDIM (Denoising Diffusion Implicit Models)
A faster variant introduced in 2021 that can skip steps without sacrificing quality. Instead of taking every tiny step from noise to image, DDIM can jump between states more aggressively.
Strengths: 10-50x faster than DDPM while maintaining similar quality. More deterministic, same seed produces more consistent results.
Weaknesses: Slightly less smooth transitions between steps, can occasionally produce artifacts if too few steps are used.
Best for: Most practical applications where speed matters but quality must remain high.
Latent Diffusion Models (LDM / Stable Diffusion)
The breakthrough that made diffusion models accessible to everyone. Instead of working in pixel space, LDMs operate in compressed latent space using a VAE.
Strengths: Dramatically lower computational requirements, runs on consumer GPUs. Maintains quality while being far more efficient. Foundation for open-source Stable Diffusion.
Weaknesses: VAE compression can occasionally lose fine details. More complex architecture means more potential failure points.
Best for: Consumer applications, open-source implementations, situations requiring efficiency.
Cascade Diffusion Models
A multi-stage approach where low-resolution images are generated first, then progressively upscaled through multiple diffusion stages. DALL-E 2 uses this architecture.
Strengths: Excellent at generating extremely high-resolution images. Each stage can specialize in different aspects (composition vs. details).
Weaknesses: Complex to train and deploy. Requires running multiple models sequentially.
Best for: Applications needing very high resolutions, complex scenes with multiple levels of detail.
Conditional Diffusion Models
Models trained with additional conditioning inputs beyond text, class labels, segmentation maps, depth information, etc. ControlNet is the most famous example.
Strengths: Unprecedented control over generation. Can follow precise structural guidance while maintaining creative freedom.
Weaknesses: Requires creating or extracting conditioning inputs. More complex workflow.
Best for: Professional applications, situations requiring precise composition control, character consistency.
Real-World Applications Transforming Creative Industries
Diffusion models aren't just tech demos, they're actively reshaping how professionals create visual content across multiple industries.
Concept Art and Entertainment Design
Game developers and film studios use diffusion models to rapidly prototype:
- Character designs with multiple style variations
- Environment concepts for world-building
- Prop and costume designs
- Storyboard generation and scene planning
Instead of commissioning dozens of concept sketches that take weeks, art directors can explore hundreds of directions in days, then have artists refine the most promising concepts.
Marketing and Advertising Content
Marketing teams leverage diffusion models for:
- Product visualization in different contexts and styles
- Social media content generation at scale
- A/B testing visual concepts before expensive photo shoots
- Creating diverse model representations without casting costs
- Seasonal campaign variations
A campaign that previously required multiple photo shoots can now test visual concepts in hours instead of weeks.
Architectural Visualization
Architects and interior designers use diffusion models to:
- Generate realistic renderings from sketches
- Experiment with different materials and lighting
- Show clients multiple design options
- Create atmospheric presentation images
- Visualize landscapes and exterior contexts
Fashion and Product Design
Fashion designers leverage diffusion models to:
- Visualize clothing designs on various body types
- Experiment with patterns and fabric textures
- Create lookbooks without physical samples
- Design accessories and product variations
Medical and Scientific Visualization
Researchers use diffusion models for:
- Generating synthetic medical training data
- Visualizing molecular structures
- Creating educational diagrams
- Augmenting limited medical imaging datasets
Current Limitations You Should Know About
Despite their impressive capabilities, diffusion models still struggle with specific challenges. Understanding these limitations helps set realistic expectations and guides better prompting strategies.
Text Rendering Problems
Diffusion models consistently struggle to generate readable text within images. You'll notice:
- Letters that look text-like but are gibberish
- Jumbled or misspelled words
- Inconsistent fonts and sizing
- Text that degrades into texture patterns
Why this happens: Models learn text as visual patterns, not as language with meaning. They see letters as shapes without understanding spelling or semantics.
Workaround: Generate images without text, then add text in post-processing using graphic design tools.
Complex Spatial Reasoning Failures
Diffusion models can confuse spatial relationships:
- "A book on top of a table" might generate the table on the book
- "Person A standing behind person B" might reverse the positions
- Complex arrangements like "three cats in a pyramid formation" often fail
Why this happens: Models learn correlations between visual elements but don't truly understand 3D space or physical constraints.
Workaround: Use ControlNet with depth maps or sketches to enforce spatial relationships.
Counting and Quantity Issues
Ask for "exactly five apples" and you might get three, or seven, or an ambiguous cluster. Precise counting is remarkably difficult for diffusion models.
Why this happens: During training, the model sees "several apples" as a visual pattern rather than learning discrete counting.
Workaround: Generate with approximate quantities, then edit in post-processing for precision.
Consistency Across Generations
Generating the same character or object consistently across multiple images remains challenging. Each generation is independent, so:
- Character features change between images
- Brand elements don't maintain exact appearance
- Scene continuity requires careful prompting
Why this happens: The random noise starting point and stochastic denoising process mean each generation explores different paths through possibility space.
Workaround: Use techniques like Textual Inversion, DreamBooth, or LoRA to train on specific subjects. Reference images and img2img also help.
Understanding Abstract Concepts
Diffusion models excel with concrete visual concepts but struggle with abstract ideas lacking clear visual training data:
- "Democracy" or "justice" without visual metaphors
- Emotional states without facial expressions
- Novel combinations never seen in training data
Why this happens: Models can only recombine visual patterns they've encountered during training.
Workaround: Use specific visual metaphors and detailed descriptive language rather than abstract terms.
The Cutting Edge: What's Coming in 2025 and Beyond
Diffusion model research is advancing rapidly. Here are the most exciting developments currently emerging from research labs and making their way into production tools.
Ultra-Fast Sampling Methods
New techniques are reducing the number of steps needed for high-quality generation:
Consistency Models: Generate images in just 1-4 steps instead of 20-50, achieving 10-50x speedups while maintaining quality. This makes real-time generation possible.
Progressive Distillation: Train smaller "student" models that learn to mimic larger "teacher" models but with fewer parameters and faster inference.
Adversarial Diffusion: Combining GAN techniques with diffusion for faster convergence without sacrificing the stability diffusion provides.
Impact: Real-time AI art becomes feasible, imagine adjusting a slider and watching your image update instantly, like traditional photo editing but with AI generation.
Video Diffusion Models
The next frontier is consistent video generation. Models like Runway Gen-2, Pika, and the upcoming Stable Video Diffusion work by:
- Applying diffusion across temporal dimensions, not just spatial
- Maintaining consistency between frames
- Understanding motion and physics
- Supporting camera movement and dynamic scenes
Current challenges include computational intensity (video is 30+ images per second) and maintaining long-term consistency, but progress is rapid.
3D Object Generation
Diffusion models are expanding into three dimensions:
NeRF + Diffusion: Combining neural radiance fields with diffusion to generate 3D objects from text or images.
Point Cloud Diffusion: Generating 3D structures as point clouds that can be converted to meshes.
Multi-view Consistency: Ensuring generated objects look correct from any angle.
Impact: Game asset generation, 3D printing design, AR/VR content creation all become faster and more accessible.
Multi-Modal Models
Future diffusion models will handle multiple data types simultaneously:
- Text + Image + Audio: Generate videos with synchronized sound effects and music
- Depth + Color + Normal Maps: Complete material generation for 3D rendering
- Sketch + Description + Style Reference: More precise control over output
Enhanced Control and Editability
New research focuses on making generation more controllable:
Semantic Guidance: Direct control over specific attributes (age, expression, lighting) through learned embeddings.
Compositional Generation: Combine multiple concepts precisely without interference.
Interactive Editing: Adjust specific elements after generation without regenerating everything.
Style Transfer Improvements: Separate content from style more cleanly, enabling better artistic control.
Addressing Current Limitations
Research specifically targeting known problems:
- Text Rendering: Specialized modules for generating readable text within images
- Spatial Reasoning: Integration with 3D scene understanding and physics engines
- Consistency: Identity-preserving generation techniques for character consistency
- Efficiency: Running diffusion models on mobile devices and in browsers
How to Get Better Results from Diffusion Models
Understanding how diffusion models work helps you use them more effectively. Here are practical tips based on the technology:
Prompt Engineering Strategies
Be Specific About Visual Elements: Instead of "a beautiful landscape," try "a mountain valley at sunset with golden lighting, pine trees in foreground, snow-capped peaks, dramatic clouds, photorealistic, 8k detail."
Use Art Direction Terms: The model understands photography and art terminology: "shallow depth of field," "golden hour lighting," "rule of thirds," "Dutch angle," "chiaroscuro."
Reference Styles Explicitly: "In the style of Studio Ghibli," "like a Renaissance painting," "digital art trending on ArtStation," "cinematic still from a Wes Anderson film."
Specify What You Don't Want: Negative prompts work because they guide the denoising away from certain visual patterns: "blurry, low quality, distorted, amateur, watermark."
Settings and Parameters
Steps (20-50 typically): More steps generally mean higher quality but diminishing returns after 40-50. Quick drafts work fine at 15-20 steps.
CFG Scale (5-15 typically): Controls how closely the model follows your prompt. Lower values (5-7) allow more creative freedom, higher values (12-15) stick rigidly to your description but can oversaturate or distort.
Sampler Choice: Different samplers (Euler, DPM++, DDIM) take different paths through the denoising process. Experiment to find which works best for your style. Euler is fast and versatile, DPM++ often gives cleaner results.
Seed Control: Using the same seed with the same prompt produces consistent results. Save seeds from successful generations to iterate on them.
Advanced Techniques
Img2Img Refinement: Generate an initial image, then use it as input with low denoising strength (0.3-0.5) to refine details while preserving composition.
Inpainting for Fixes: Instead of regenerating entire images, mask problem areas and inpaint just those regions.
ControlNet for Precision: Use edge detection, depth maps, or pose detection to control composition precisely while letting the model handle stylistic details.
LoRA and Fine-Tuning: For consistent characters, brands, or specific styles, train custom LoRAs on 20-100 reference images.
Popular Diffusion Model Tools in 2025
Stable Diffusion XL (Open Source)
The most accessible option, with complete control over the generation process. Can be run locally on consumer hardware with 8GB+ VRAM, or accessed through services like Stability AI's platform.
Best for: Developers, researchers, users wanting complete control and customization, budget-conscious creators.
Midjourney v6
Discord-based service known for exceptional aesthetic quality and artistic interpretation. Strong at understanding complex, poetic prompts.
Best for: Artists, designers wanting high-quality results without technical setup, stylized and artistic content.
DALL-E 3 (via ChatGPT)
Integrated with ChatGPT, excelling at understanding natural language descriptions and generating images that precisely match prompts.
Best for: Users wanting conversational interaction, precise prompt interpretation, integration with text-based workflows.
Adobe Firefly
Commercially safe diffusion model trained only on licensed content. Integrated directly into Photoshop and other Adobe products.
Best for: Professional commercial work, users needing copyright safety, seamless integration with design workflows.
Leonardo.ai
Game asset and production-focused platform with fine-tuned models for specific use cases like character design, environments, and props.
Best for: Game developers, production artists, users needing consistent asset generation.
Ethical Considerations and Responsible Use
As someone who understands how diffusion models work, you have a responsibility to use them ethically.
Copyright and Training Data Concerns
Diffusion models are trained on billions of images scraped from the internet, raising complex questions:
- Artist Consent: Many artists' works were used in training without permission or compensation
- Style Mimicry: Models can replicate specific artists' styles, potentially devaluing their unique creative voice
- Copyright Gray Areas: Legal questions about whether generated images infringe on training data remain unsettled
Best Practices: Use models trained on licensed content when possible (Adobe Firefly, Shutterstock AI), avoid directly copying living artists' styles, credit when AI is used in your work, and support legislation that protects artists' rights.
Deepfakes and Misinformation
The same technology creating art can generate misleading or harmful content:
- Fake news images that appear photorealistic
- Non-consensual imagery of real people
- Manipulated historical or documentary photos
Best Practices: Clearly label AI-generated content, don't create images impersonating real people without consent, refuse to generate misleading content even if technically possible.
Bias and Representation
Training data biases get encoded into diffusion models:
- Gender stereotypes in occupational prompts
- Racial biases in beauty and professionalism depictions
- Cultural stereotypes and underrepresentation
Best Practices: Be aware of default outputs and actively prompt for diversity, test your generations for bias, use models that have been specifically debiased when available.
Environmental Impact
Training large diffusion models requires substantial computational resources:
- Training Stable Diffusion XL cost an estimated 600,000 GPU hours
- Carbon footprint equivalent to years of average household emissions
- Ongoing inference costs accumulate across millions of users
Best Practices: Generate thoughtfully rather than wastefully, use efficient models and sampling methods, support development of more efficient architectures.
Learning Resources for Going Deeper
If this guide sparked your interest in understanding diffusion models at a deeper level, here are trusted resources:
Technical Papers
- "Denoising Diffusion Probabilistic Models" (Ho et al., 2020): The foundational DDPM paper
- "High-Resolution Image Synthesis with Latent Diffusion Models" (Rombach et al., 2022): The Stable Diffusion architecture
- "Scalable Diffusion Models with Transformers" (Peebles & Xie, 2023): Next-generation architectures
Video Tutorials and Courses
- Fast.ai Practical Deep Learning: Includes accessible explanations of diffusion models
- Hugging Face Diffusion Models Course: Hands-on implementation tutorials
- Two Minute Papers (YouTube): Accessible explanations of the latest research
Communities and Forums
- r/StableDiffusion: Active community sharing techniques and troubleshooting
- Civitai: Model sharing platform with extensive tutorials
- Hugging Face Forums: Technical discussions and implementation help
Frequently Asked Questions
How long does it take to generate an image with diffusion models?
On modern GPUs (RTX 3080 or better), Stable Diffusion generates a 512-512 image in 5-10 seconds, 1024-1024 in 15-30 seconds. Cloud services like Midjourney typically take 30-60 seconds. Mobile and web-based tools may take 1-3 minutes. The exact time depends on resolution, number of steps, and hardware.
Can I run diffusion models on my own computer?
Yes, if you have a decent GPU. Stable Diffusion requires:
- Minimum: 8GB VRAM (NVIDIA RTX 3060, AMD RX 6800) for 512-512 images
- Recommended: 12GB+ VRAM (RTX 3080, 4070) for 1024-1024 and faster generation
- CPU-only: Possible but extremely slow (5-10 minutes per image)
Apple Silicon Macs with 16GB+ unified memory can run Stable Diffusion reasonably well using optimized implementations.
Are AI-generated images copyrightable?
This remains legally unsettled and varies by jurisdiction. Current U.S. Copyright Office guidance suggests AI-generated images without significant human creative input may not be copyrightable. However, images created through substantial human direction, curation, and editing may qualify. Consult a legal professional for specific use cases.
How do diffusion models compare to other AI image generators?
Diffusion models currently dominate because they offer the best combination of quality, controllability, and flexibility. GANs (the previous leading technology) are faster but less stable and controllable. Transformer-based models show promise but require even more computational resources. For most applications in 2025, diffusion models are the practical choice.
Can diffusion models generate videos?
Yes, video diffusion models exist (Runway Gen-2, Pika, Stable Video Diffusion) but remain more limited than image models. Current challenges include maintaining consistency across frames, computational costs, and shorter maximum durations (4-8 seconds typically). This is an active area of rapid development.
Why do diffusion models sometimes fail to generate what I ask for?
Several reasons: your prompt may contain conflicting concepts, the model may not have seen similar examples in training data, or the random noise starting point may have led down an incorrect path. Solutions include rephrasing prompts more specifically, adjusting CFG scale, trying different seeds, or using img2img with a reference.
Final Thoughts: The Future Is Collaborative
Diffusion models represent one of the most significant breakthroughs in creative AI technology. By learning to reverse entropy, to find meaningful signal within pure noise, they've unlocked capabilities that seemed impossible just five years ago.
But understanding how they work reveals an important truth: these are tools, not replacements. The "AI" in AI art stands for "Artificially Intelligent," but also for "Artist Integrated." The most compelling AI-generated content comes from creators who understand both the technology and their artistic vision, using diffusion models as collaborators rather than automated replacements.

As diffusion models continue evolving, becoming faster, more controllable, and more capable, they'll transform from novelty tools into fundamental creative instruments. Just as photographers don't need to understand sensor physics to take great photos, future creators won't need to know the mathematics of denoising. But understanding the principles helps you push boundaries and solve problems creatively.
The conversation about AI art will continue evolving alongside the technology. Questions about authorship, creativity, originality, and artistic value remain complex and contested. What's certain is that diffusion models have permanently expanded what's possible in visual creation. Whether you're a professional artist, a hobbyist, or simply curious about technology, understanding how diffusion models work gives you the foundation to participate meaningfully in this creative revolution.
The tools are here. The technology is accessible. Now it's up to human creativity to determine what we build with these remarkable new capabilities. Welcome to the future of visual creation, where your imagination is the only real limit.